Adatok
TimeToLive
0 bejegyzést írt és 15 hozzászólása volt az általa látogatott blogokban.
Néhány éve kezembe került Robert Axelrod talán leghíresebb könyve, mely a fogolydilemmával foglalkozik: egy egyszerű példa, hogy mikor éri meg együttműködni és mikor nem.A játékban két szereplő van, akiket a rendőrség elfogott, elkülönített és tanúzásra szólított fel.…..
TimeToLive
2011.01.08 20:08:51
@Haibane: Szervusz!
"Természetesen nem volt célom egy blogpostban az egész játékelméleti hátteret bemutatni, mert gondolom belátod, hogy ez nem lehetséges"
Persze, nem is az volt a célom, hogy kritizáljalak. Csak egy diszkussziót akartam kezdeményezni, miszerint az önzés akár hosszú távon is hasznos lehet, és nem feltétlenül káros a köz számára. Továbbá eddigi kutatásaim során számomra nagyon is úgy tűnik, hogy az önzés önmagában is hordoz együttmüködést (meta szinten), ha az ágens képes tanulni és a környezeti változásokhoz adaptálni.
Vagyis az önzés nem fehér-fekete valami. Erre mondtam az elején hogy a helyzet kicsit bonyolultabb (szerintem), mint amit te állítasz.
"Természetesen nem volt célom egy blogpostban az egész játékelméleti hátteret bemutatni, mert gondolom belátod, hogy ez nem lehetséges"
Persze, nem is az volt a célom, hogy kritizáljalak. Csak egy diszkussziót akartam kezdeményezni, miszerint az önzés akár hosszú távon is hasznos lehet, és nem feltétlenül káros a köz számára. Továbbá eddigi kutatásaim során számomra nagyon is úgy tűnik, hogy az önzés önmagában is hordoz együttmüködést (meta szinten), ha az ágens képes tanulni és a környezeti változásokhoz adaptálni.
Vagyis az önzés nem fehér-fekete valami. Erre mondtam az elején hogy a helyzet kicsit bonyolultabb (szerintem), mint amit te állítasz.
TimeToLive
2012.11.13 12:36:01
@Haibane: Bocsánat a késői válasszért, de rég nem jártam erre :)
Szóval ha érdekel a téma, akkor érdemes körülnézned a köv. területeken:
1. klasszikus game theory esetén fictitious play, amikor az ellenfelek stratégiáját lemodellezzük, és asszerint számítjuk ki a BR-t. Ez önmagában is hordozhatja a lehetséges együttmüködést
2. Evolutional game theory - elég sok cikk azzal foglalkozik hogy stabil populációk esetén a csupa önző ill. csupa kooperatív egyedekből álló halmazok összteljesítménye nem mindig a legjobb. Így kell vmilyen egyensúly. Persze ehhez a modellt kicsit módosítani kell, pl. bevezetni a befolyásolhatósági tényezőt: egy ágens sikeres stratégiáját mennyire akarja adoptálni a szomszédjai.
3. Behavioural game theory: ez egy nagyon új és érdekes területe a játékelméletnek. Itt mivel az ágensek nem feltétlenül hasonló szintű racionálitással tudnak gondolkodni (korlátozott info vagy erőforrás miatt), az önzés néha jól jön (pl. nem szimmetrikusak a célok). Erre egy nagyon érdekes példa a pár éve Martin Zinkevich (Yahoo/Google) és Mike Bowling (univ. of Alberta) által elindított Lemonade Stand Game (dl.acm.org/citation.cfm?id=1978730)
A játékban 3 játékos található, akiknek vmilyen célfv-t kell maximalizálniuk úgy, hogy nem kommunikálhatnak egymással. Viszont együttmükődés nélkül nem lehet a játékot megnyerni. Így az igazi (hosszútávú) önző stratégiáknak figyelembe kell venniük a rövidtávú együttmüködést :)
érdemes elolvasni a 2010es verseny nyertes csapatának az UAI-s cikkét:
eprints.soton.ac.uk/271215/1/ECAI-604.PDF
Szóval ha érdekel a téma, akkor érdemes körülnézned a köv. területeken:
1. klasszikus game theory esetén fictitious play, amikor az ellenfelek stratégiáját lemodellezzük, és asszerint számítjuk ki a BR-t. Ez önmagában is hordozhatja a lehetséges együttmüködést
2. Evolutional game theory - elég sok cikk azzal foglalkozik hogy stabil populációk esetén a csupa önző ill. csupa kooperatív egyedekből álló halmazok összteljesítménye nem mindig a legjobb. Így kell vmilyen egyensúly. Persze ehhez a modellt kicsit módosítani kell, pl. bevezetni a befolyásolhatósági tényezőt: egy ágens sikeres stratégiáját mennyire akarja adoptálni a szomszédjai.
3. Behavioural game theory: ez egy nagyon új és érdekes területe a játékelméletnek. Itt mivel az ágensek nem feltétlenül hasonló szintű racionálitással tudnak gondolkodni (korlátozott info vagy erőforrás miatt), az önzés néha jól jön (pl. nem szimmetrikusak a célok). Erre egy nagyon érdekes példa a pár éve Martin Zinkevich (Yahoo/Google) és Mike Bowling (univ. of Alberta) által elindított Lemonade Stand Game (dl.acm.org/citation.cfm?id=1978730)
A játékban 3 játékos található, akiknek vmilyen célfv-t kell maximalizálniuk úgy, hogy nem kommunikálhatnak egymással. Viszont együttmükődés nélkül nem lehet a játékot megnyerni. Így az igazi (hosszútávú) önző stratégiáknak figyelembe kell venniük a rövidtávú együttmüködést :)
érdemes elolvasni a 2010es verseny nyertes csapatának az UAI-s cikkét:
eprints.soton.ac.uk/271215/1/ECAI-604.PDF

A MIT kutatói olyan autonóm robotokat teveztek, amik a Mexikói-öbölből felitatják a tengeren úszó olajfoltokat. Az elképzelések szerint a robot-tutajok egymással kommunikálva derítenék fel és tüntetnék el a szennyeződést.
A hagyományos körbekerítésen és szivattyúzáson…..

A komplexitás-tudomány olyan rendszereket, ágensekkel, ágensrendszerekkel jól szimulálható önszerveződő folyamatokat próbál értelmezni, amelyekben a rendszerszintű viselkedésformák nem közvetlen következményei a részek közti interakcióknak. A nemzetközi ágenskutatás egyik…..
TimeToLive
2010.08.27 11:40:36
@pannonfunk: Sajnos a spanyolviasz jelenseg eleg gyakori a tudomany vilagaban. Ugyanis a kulonbozo tudomanyagak muveloi nem nagyon kommunikalnak egymassal.
Pl. siman elofordulhat, hogy neves MI konferenciakon olyan eredmenyeket mutatnak be ujnak, melyeket mar publikaltak par evvel elotte jatekelmeleti forumokon.
Mondjuk ez azert annyira nem rossz hir, mert ez azt jelenti, hogy bar a koncepcio azonos, es a konkluzio is hasonlo, maguk a modszerek masok lehetnek. Ezen kivul azt is mutatja, hogy az adott problemat tobb szemszogbol is meg lehet kozeliteni, es ilyenkor tudomanyagak kozti egyuttmukodesek johetnek letre. Ezt pedig nagyon szeretik az emberek :)
Pl. siman elofordulhat, hogy neves MI konferenciakon olyan eredmenyeket mutatnak be ujnak, melyeket mar publikaltak par evvel elotte jatekelmeleti forumokon.
Mondjuk ez azert annyira nem rossz hir, mert ez azt jelenti, hogy bar a koncepcio azonos, es a konkluzio is hasonlo, maguk a modszerek masok lehetnek. Ezen kivul azt is mutatja, hogy az adott problemat tobb szemszogbol is meg lehet kozeliteni, es ilyenkor tudomanyagak kozti egyuttmukodesek johetnek letre. Ezt pedig nagyon szeretik az emberek :)

Ha azt mondanám, hogy az embereket leigázó robotok csak a modern kor szülöttei lennének, igencsak tévednék. Elegendő visszatekinteni Asimov munkáira, különösen az 50-es évekből mikor a mesterséges intelligencia mint tudományos kifejezés és elmélet útnak indult.…..
TimeToLive
2010.08.23 00:49:46
@wmiki: pedig az ember is algoritmusok szerint mukodik :)
Mas kerdes, hogy mennyire bonyolult egy-egy algoritmusnak a leirasa (a bonyolultsagot tobbek kozott pl a Kolmogorov bonyolultsaggal lehet leirni), illetve annak hardveres megvalositasa.
Ezen kivul az is kerdeses, mennyire hatekony a leirt algoritmus (pl. idobeli koltseget nezve stb.)
Igy tehat az igazi kerdes nem az, hogy akkor algoritmussal (mechanizmussal, policy-vel stb) le lehet-e irni a kivant viselkedesi format, hanem az, hogy mennyire bonyolultan tudjuk csak megtenni a jelenlegi tudasunkkal.
Magyaran szolva az altalad emlitett intelligencia meg kreavititas is tobbe-kevesbe algoritmizalhato, csak kerdes hogy az mennyire lesz megvalosithato, leven hogy perpillanat korlatosak a kapacitasaink szoftver es hardver szinten is.
Mas kerdes, hogy mennyire bonyolult egy-egy algoritmusnak a leirasa (a bonyolultsagot tobbek kozott pl a Kolmogorov bonyolultsaggal lehet leirni), illetve annak hardveres megvalositasa.
Ezen kivul az is kerdeses, mennyire hatekony a leirt algoritmus (pl. idobeli koltseget nezve stb.)
Igy tehat az igazi kerdes nem az, hogy akkor algoritmussal (mechanizmussal, policy-vel stb) le lehet-e irni a kivant viselkedesi format, hanem az, hogy mennyire bonyolultan tudjuk csak megtenni a jelenlegi tudasunkkal.
Magyaran szolva az altalad emlitett intelligencia meg kreavititas is tobbe-kevesbe algoritmizalhato, csak kerdes hogy az mennyire lesz megvalosithato, leven hogy perpillanat korlatosak a kapacitasaink szoftver es hardver szinten is.
Ezt a bejegyzést egyfajta alapozásnak szánnám, úgy gondolom fontos egy kicsit beszélni az alap gondolatokról, célokról és lehetőségekről, mégha ez sok ember számára triviális is. Tudom, hogy ezt talán a blog kezdetekor kellett volna megírni, de csak most jutott rá…..
TimeToLive
2010.04.29 00:06:59
@stnksrbtks:azert nincs olyan messze az a nyugat :) Lehet hogy mar ismered, de Andrew Ng honlapjan jo dolgokat talalhatsz inverse RL-lel kapcsolatban.
TimeToLive
2010.04.26 01:34:25
@stnksrbtks: Mar nem is emlekszem, de valoszinuleg anno egy ismerosom beszelt rola :) Amugy ez a reward shaping egy fajtaja, ismeretlen kornyezetben. Sajnos ezt a teruletet sem ismerem igazan, de a kollegaim kozul sokan reward shaping-gel foglalkoznak.
Amugy te vmilyen robot tanitasra hasznalod az inverse RL-t? :)
Amugy te vmilyen robot tanitasra hasznalod az inverse RL-t? :)
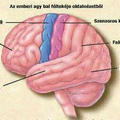
Az előző írásban kicsit áttekintettük az agy felépítését és a tanulás folyamatát, melyről megállapítottuk, hogy asszociáción alapszik, majd megismertük az alapvető különbséget az emberi és a gépi emlékezet között. Jelen írásban ezt a gondolatsort szeretném folytatni…..
TimeToLive
2010.04.21 13:23:06
TimeToLive
2010.04.21 16:25:30
@brlv24: Ha nem tevedek nagyot, akkor jelenleg azert kevesbe elfogadott a neuralis halos modszer meg, mert nagyon sokaig (Minskynek koszonhetoen) a perceptronos vonalat zsakutcanak tekintettek.
Szerintem sok potencial van benne, plane ha kombinaljuk mas tanulasi modszerekkel is :)
Szerintem sok potencial van benne, plane ha kombinaljuk mas tanulasi modszerekkel is :)

Imre fotója alapján elképzelhető, hogy macskainvázió tört ki Pécsen. Az elszaporodott ragadozók besurrannak a megyei kórházba és a magatehetetlen betegek tálcájáról lakmároznak: A Backdoor rovatba küldök itt egy képet: a pécsi megyei kórházban készült. Egy hátsó…..
TimeToLive
2009.04.07 14:51:39
Belépve többet láthatsz. Itt beléphetsz
Szerintem ennél azért egy kicsivel bonyolultabb a helyzet.Ugyanis meglepő módon az önző viselkedés magában foglalhatja a kooperációt is.
Hogy részletesebb legyek, vizsgáljuk meg a játékelméleti modelleket közelebbről. A játékelméletben minden játékos racionális döntéseket hoz, azaz mindig arra törekszik, hogy az adott helyzetben a lehető legjobb lépést tegye meg. Ezt hívják best response (BR) stratégiának. Ez a BR stratégia egyébként az önző viselkedés modellje (maga az önzés mint kifejezés csak sokkal később, az autonóm ágenseknél kerül először elő).
Most vegyük szemügyre az általános klasszikus játékelméleti modellt. Itt minden játékos csak a jelen állapot szerint hoz döntést, azaz senki sem rendelkezik memóriával. Ilyenkor a BR döntés az aktuális állapothoz képest BR.
Most, ha sokáig játszanak, akkor jobb esetben a játék konvergál egy egyensúlyi állapothoz, ezt hívják Nash egyensúlyi pontnak (NEP).
Viszont a NEP lehet hogy a szükséges rossz megoldás mindenki számára, és más stratégia profilok sokkal jobb összeredményt hozhatna (Pareto-hatékony). Azaz mindenki az adott körülményekhez képest a BR-t választja, viszont ezáltal mindenki rosszul jár. Tipikus példa erre a cikkben is megemlített fogolydilemma.
Vagyis a klasszikus modellben teljesen igazad van, hogy az önzés megöli a közös sikert.
De amint látjuk, a klasszikus modell nagyon messze áll a valós modellektől, így manapság már érdemben nem is nagyon foglalkoznak vele. Ellenben különféle kiterjesztett modelleket dolgoztak ki az utóbbi 30 évben.
Az egyik ilyen modell a memóriával rendelkező játék. Ebben minden játékos megjegyzi, hogy a többiek milyen döntéseket hoztak az elmúlt "k" körben. Ennek segítségével képesek az ellenfelek stratégia policy-jét "megtanulni" (ilyen tanulási módszer pl. a bounded reasoning - "én úgy gondolom hogy te úgy gondolod hogy én úgy gondolom stb", a fictitious play, vagy a Bayes tanulás). Miután a játékos megtanulta az ellenfelei policy-eit, képes lesz olyan BR döntést hozni, ami nem csak rövid távon, hanem hosszú távon is eredményes. Na most, ha minden játékos ily módon tanul és figyeli a többit, a tanulási folyamat során óhatatlanul egyfajta metakommunikációt folytatnak egymással ( a döntéseiken keresztül kommunikálnak egymással) .
Ilyenkor az az érdekes dolog történik, hogy hiába mindenki a saját BR stratégiáját követi, ebben a BR-ban már implicite kódolva van az együttmüködés.
Tehát külsőre mindenki önző, mert BR-t választ, de közben belül már bizonyos szintű kooperáció zajlik.Ez azért egy kicsit más mint az 1. kijelentésed, mert ott te explicit szabály segítségével kényszeríted a játékosokat kooperációra, míg az általam leírt modellben maga a játékos még mindig azt hiszi, hogy önző.
Amúgy ez az önzésbe kódolt együttmüködés még nagyon új, és tiszta elméleti eredmények még nem születtek, csak hipotésizek és számos sikeres alkalmazás (főként szenzorosak).
Végül még vmi: a 2. kijelentéseddel a matematika és a számításelmélet egy (sztem viszonylag fontos, de sajnos alulértékelt) területe, a stabilitáselmélet foglalkozik. Itt a kérdés az, hogy ha adott 1 függvény (játék), melynek az optimális pontját (pl. NEP) kell megkeresni, akkor ha a függvény paramétereit kis mértékben módosítjuk, akkor mennyire változik az optimális pont.
Erre már született számos szép eredmény, szal érdemes utánanézni.
Amúgy a változtatás amit említettél a cikkben, az nem kis változtatás. Ugyanis azáltal hogy másképp osztod szét a pénzt, az eredeti játékmodellt átalakottad egy másik típusú játékká. Ezt az új modellt úgy hívják hogy koalíciós játékmodell, és teljesen más dinamikával és jellemzőkkel bír, mint az eredeti klasszikus modell.